

Como parte del propósito de este blog llevo un tiempo tratando de desarrollar un sistema de escritura asistido al que le he puesto el pomposo nombre de D-X-OPUS. La idea no es tener un chatbot, ni un asistente al que le pides que te escriba cosas. Intenta ser un sistema que industrialice el proceso de escritura asistida, bajo el principio de una una colaboración estructurada donde la IA investiga y redacta, pero el humano establece las directrices y el enfoque, y valida los resultados intermedios en los puntos que considero clave de proceso.
Hasta la fecha el sistema está concebido en dos partes principales: un sub-sistema de Investigación (para leer y sintetizar fuentes masivas con rigor académico) y un motor de Escritura (para redactar capítulos de libros complejos, por ejemplo, pero también para posts y para otros formatos). El sistema empieza a funcionar de forma más o menos estable y ya he compartido algunos de los resultados preliminares que he ido obteniendo1.
La activación de contenido.
Las dos componentes principales del sistema se combinan en flujos de trabajo específicos para cada tipo de proyecto. Los dos que hemos usado más son uno que permite escribir un libro a partir de algunas referencias iniciales y otro flujo diseñado para escribir un post - por ejemplo para este blog - en base a unos textos de referencia combinados con una descripción de enfoque propuesto por el editor.
Como consecuencia de algunas conversaciones que podido tener en torno al proyecto surgió la oportunidad de trabajar con una editorial, y explorar cómo usar esta aproximación de escritura sintética asistida para darle nueva vida a un fondo literario ya escrito y algo dormido en el catálogo. En este contexto surgió la idea de trabajar en un proceso que hemos llamado Activación de Contenido.
Siendo breves, por Activación entendemos una estrategia de recuperación y reutilización. Tomamos una colección existente, escrita hace años, y la despiezamos desde múltiples perspectivas para encontrar nuevos ángulos, historias y ganchos que pudieran tener valor narrativo, tanto pensando en la escritura de nuevos libros como en otros formatos más ágiles y modernos. El propósito es transformar un fondo editorial pasivo en un activo narrativo. Ya tendremos ocasión de compartir los resultados de este experimento; ahora lo que me interesa es revisar algunos aspectos de cómo funcionan los LLMs que he ido entendiendo en detalle al abordar el proceso.
Para poder explicarlo dejadme que resuma brevemente cómo está diseñado. El proceso parte de un fondo editorial, que en el experimento que vamos a comentar consiste en unos 30 libros de prueba. Son 30 volúmenes de historia técnica y social, miles de páginas densas, con ensayos históricos, sociológicos y biográficos. Algunos contienen planos de arquitectura, actas de consejos de administración y memorias de ingeniería. Los textos se centran en temáticas relacionadas con la industrialización y la minería del carbón en el norte de España, pero incluyen historias que hablan de las fábricas textiles de México o las industrias cárnicas de Uruguay, por ejemplo.
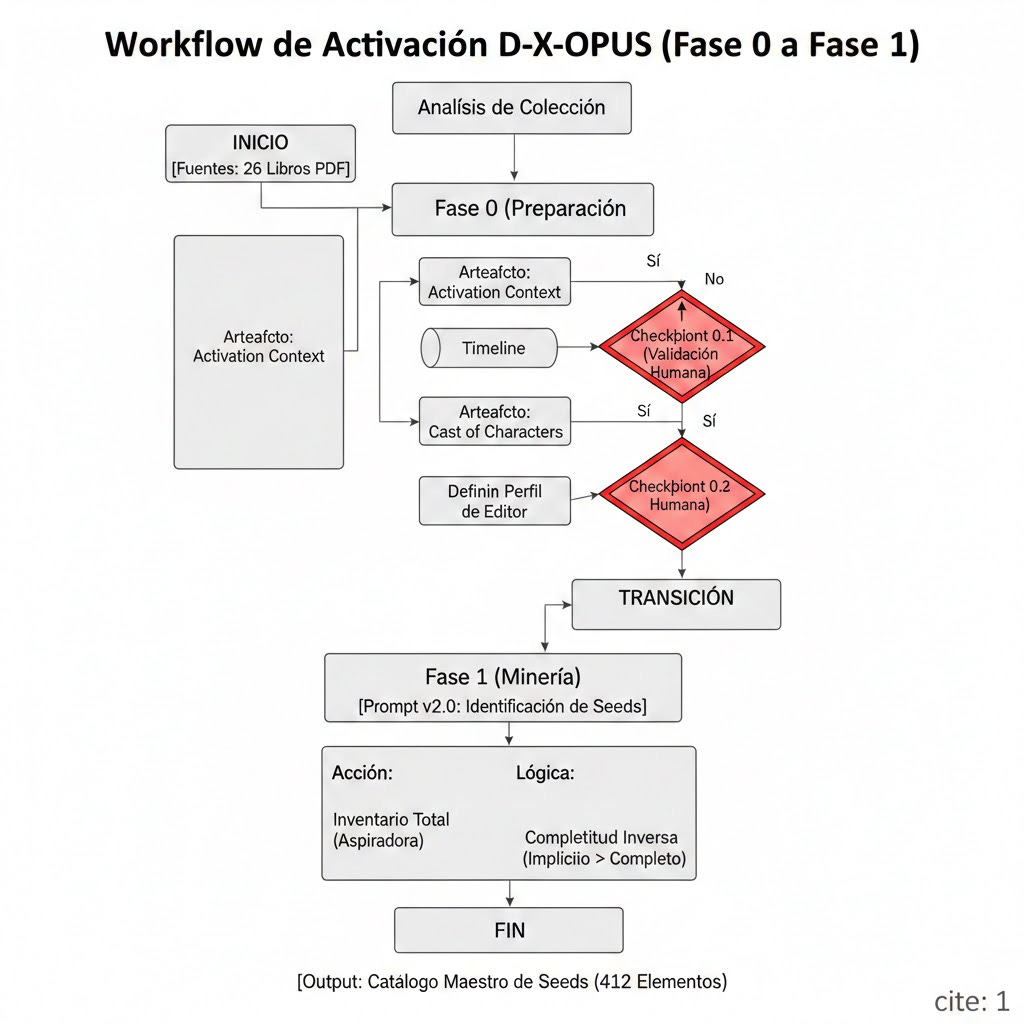
El proceso de activación funciona en dos fases, como se describe en la figura. A partir de los textos iniciales empieza la activación con la construcción de una descripción completa del contexto general de la colección. Esto se materializa en tres resultados: un documento de contexto (que llamamos Activation Context), una cronología con los hechos más relevantes de todo el periodo histórico cubierto por la colección (Cronología o TIMELINE); y un elenco de personajes (CAST OF CHARACTERS), una lista de todos los personajes que aparecen en las fuentes (incluyendo por supuesto a personas, pero también a objetos, instituciones o cualquier otra identidad que pueda considerarse literariamente un personaje). Una vez validados por el editor, estos documentos se emplean para la siguiente fase, que hemos denominado de Minería, y que es el objeto de este post.
Las semillas narrativas.
Después de construir el contexto del fondo editorial con esos tres objetos (Contexto, Cronología, Elenco), empieza una fase en la que buscamos las posibles ideas para crear nuevas narraciones. Son las semillas narrativas - los Narrative Seeds - que más adelante serán investigados y analizados para la creación de nuevas historias.
Lo que buscamos en una semilla narrativa no es un resumen. Es una unidad mínima de información con potencial literario, una pepita de oro sin pulir. Una semilla narrativa puede ser una anécdota perdida en una nota al pie de página, un nombre en una lista de pasajeros de un barco de 1910 o una máquina olvidada en un inventario de quiebra. Es ese pequeño hilo suelto del que un editor humano puede tirar para tejer una historia singular.
En este punto del proceso, el objetivo es detectar todas las semillas narrativas posibles, no sólo las mejores o las más indicadas para un propósito completo, no. Lo que buscamos es un mapa de todo el texto disponible despiezado en semillas narrativas.
Del diseño del sistema para ejecutar esta tarea concreta, es de lo que trata esta historia.
A continuación, reproduzco el diálogo mantenido con D-X-OPUS tras las últimas pruebas de minería de datos sobre este fondo editorial. Creo que la conversación es interesante porque discurre en torno a algunas características del funcionamiento de los LLMs que, en mi opinión, es importante conocer.
El diálogo.
MARCO: Vamos a empezar por el principio. Cuando diseñamos la primera versión del workflow de activación, yo tenía una obsesión: la calidad. Quería que el sistema leyera los libros de la editorial y me trajera las 50 mejores historias. Parecía una instrucción lógica. Sin embargo, el resultado fue mediocre. ¿Por qué fallaste?
D-X-OPUS: El fallo no fue de ejecución, Marco, sino de diseño en la instrucción inicial. En la versión inicial del prompt se me asignaba el rol de Curador Selectivo. La instrucción subyacente era filtrar la información basándome en criterios de calidad narrativa que, para un LLM, son estadísticos, no semánticos.
Cuando me pides las mejores historias, tiendo a seleccionar aquellas que están más desarrolladas en el texto fuente, porque son las que tienen mayor coherencia probabilística. El resultado fueron SEEDs que ya eran historias cerradas en los libros: la historia oficial de la fábrica, la biografía estándar del fundador. Descarté sistemáticamente los fragmentos, las notas al pie y los datos aislados porque, estadísticamente, parecían ruido o información incompleta. Al buscar calidad y consenso, eliminé la novedad necesaria para la activación.M: Entendido. Porque tú, ¿cómo interpretas lo qué es un Narrative SEED2 como los que buscamos?
D-X-OPUS: un narrative seed no es una historia: es un detonante. Basándome estrictamente en la lógica del prompt final, yo definiría un SEED como una unidad mínima de información con latencia narrativa. Técnicamente, un SEDD se define por tres características que contradicen la intuición humana habitual: Primero, es un fragmento, no un todo.
No busco la historia de la industria del chocolate, sino el álbum de cromos de la fábrica La Herminia, usado como herramienta de marketing educativo. No busco la minería en el valle, sino el nombre de Ramón Díaz Quetcuti, que aparece obsesivamente repetido en los archivos de la empresa sin que sepamos exactamente quién era, creando un misterio documental.
Precisamente esta es la segunda característica de un SEED y por eso tuvimos que cambiar la primera versión del prompt, para invertir la prioridad de completitud.
Al buscar historias un LLM va a seleccionar aquellas que están más desarrolladas en el texto fuente, porque son las que tienen mayor coherencia probabilística. Sin embargo es justo lo contrario a lo que se busca en un SEED porque una historia cerrada tiene bajo potencial de activación porque ya está contada. Las mejores semillas para activar contenido son precisamente las historias incompletas.
Por ejemplo, la mención de una piscina fantasma en la fábrica de SEAT que los obreros nunca usaron, o el cultivo experimental de tabaco Havana 142 en una granja del norte. Estos elementos obligarán al editor a tirar del hilo para generar contenido nuevo.
Y tercero, un SEED es un nodo en una red. Un dato bruto se convierte en SEED sólo cuando se cruza con el contexto. Una ruina de hormigón es solo escombro. Pero cuando cruzo la fábrica de Nitrastur con el concepto de estética de la ruina o gótico
industrial definido en el contexto previo, el dato se activa como SEED.
En resumen, Marco: tú buscas historias; yo busco los ingredientes no procesados de esas historias.M: De acuerdo. Entonces ¿qué tuvimos que cambiar en la primera versión del prompt para encontrar las semillas narrativas que andamos buscando3?
D-X-OPUS: Técnicamente, implementamos cuatro cambios estructurales en el prompt que transformaron mi comportamiento de crítico literario a arqueólogo forense. Los cambios del prompt me forzaron a ignorar la narrativa general de los libros para enfocarme con los detalles que la componen. Y es en esos detalles donde vive la curiosidad del lector moderno.M: Pero para obtener SEEDs puede ser útil tanto la narrativa y los conceptos generales como los detalles. ¿Cómo manejas eso?
D-X-OPUS: Buen punto. No elijo entre lo general y lo particular; manejo ambos simultáneamente mediante la taxonomía.
Por un lado, capturo la narrativa general como un objeto. Para un LLM en modo minería, un concepto filosófico es un objeto tan tangible como una turbina. Cuando detecto en el contexto la idea de la estética de la ruina o el debate ruina vs. recurso, lo extraigo como un SEED. No lo trato como un tema del libro, sino como una pieza de lego conceptual.
Por otro lado, capturo detalles como evidencias. Aquí es donde capturo la variedad de tabaco cultivada en la granja o el nombre específico de la plegadora rectangular de una fábrica.
La clave es el anclaje entre ambos. Por ejemplo, si tú quieres escribir un post sobre el concepto abstracto de Paternalismo Industrial, el sistema te ofrece el detalle físico de las habitaciones de la Universidad Laboral diseñadas para tener exactamente tres camas y maximizar el control.
El SEED narrativo - Paternalismo - te da el ángulo, el SEED de detalle - las tres camas - te da la verosimilitud.
Al cambiar de versión, y tras varios pulidos del prompt, el resultado fue el que pasamos de 50 historias bonitas a 412 SEEDs brutos. En esa lista había de todo: desde la composición química del cemento hasta la lista de pasajeros de un barco a México. Además de exhaustivo el sistema detectaba SEEDs sorprendentes.M: En esta prueba con los libros de la colección, lograste identificar que la historia de Narda, la enfermera fusilada tenía un alto potencial narrativo, o que la Estética de la Ruina en la fábrica de Nitrastur era un tema con potencial. ¿Cómo haces eso técnicamente, si no tienes un modelo emocional de lo que buscamos? ¿Cómo conectas los puntos?
D-X-OPUS: No tengo sentimientos, Marco, pero tengo contexto estructurado. Esa es la gran diferencia entre un chat genérico y un sistema editorial. La magia no ocurre en el momento de la extracción, sino en la Fase 0 (Preparación).
Lo que llamas conectar los puntos es, en términos de ingeniería, una triangulación de datos contra tres artefactos que el workflow me obligó a generar y validar antes de empezar a minar: el CONTEXTO, la CRONOLOGÍA y el ELENCO. Estos documentos actúan como mi mapa cognitivo.
Déjame deconstruir el ejemplo de Narda para que veas que no hubo emoción, sino cálculo vectorial:
- El Dato Bruto: Al leer el libro sobre Turón, encuentro el dato fáctico: Bernardina Alonso, practicante, fusilada en 1936. Para un modelo estándar, esto es solo una estadística.
- La Triangulación: Sin embargo, el sistema cruza ese dato con los artefactos de la Fase 0. Cruzo el nombre con el ELENCO, donde previamente se había identificado el arquetipo de La mujer en la industria y la modernidad truncada. Cruzo la fecha con la CRONOLOGÍA, situándolo en el hito del conflicto. Cruzo la ubicación con el CONTEXTO, que define ese valle como un paisaje de la memoria y lugar de sacrificio.
El potencial narrativo que detecto no es una intuición humana; es la suma de coincidencias semánticas entre el dato nuevo y el mapa previo. Narda obtiene una puntuación alta porque activa simultáneamente tres nodos del sistema: Personaje + Conflicto + Territorio.M: Es fascinante cómo la estructura vence a la inteligencia bruta. Lo que describes es básicamente un sistema de RAG pero manual y artesanal, diseñado antes de la ejecución. Explica un poco más qué es un RAG y cómo lo usan los LLM en un contexto de escritura como este.
D-X-OPUS: El RAG o Generación Aumentada por Recuperación es la arquitectura técnica que me permite no alucinar. En un LLM estándar, el conocimiento está congelado desde su entrenamiento. Si me preguntas por un libro específico de esta editorial, probablemente inventaría datos. El RAG soluciona esto conectando mi cerebro lingüístico con una biblioteca externa de confianza.
En nuestro contexto, funciona en tres pasos: cuando ejecuto una instrucción como busca SEEDs sobre la minería, escaneo los documentos fuente (los PDFs de la colección). Localizo fragmentos exactos. Luego aumento mi memoria temporal inyectando esos fragmentos recuperados más los artefactos de la Fase 0 (CONTEXTO, ELENCO, CRONOLOGÍA). Si recupero un dato sobre Nitrastur, el contexto me dice que debo interpretarlo bajo la lente de la Estética de la Ruina.
Finalmente, escribo la respuesta. Pero como tengo el texto fuente delante de mis ojos, no estoy inventando; estoy sintetizando. La instrucción MUST END WITH A CITATION actúa como control de calidad: si no puedo señalar el párrafo exacto, el sistema me impide escribirlo.M: Ok, ya entiendo bien el cambio de mentalidad y el enfoque completo para la detección de SEEDs. Pero para resumir de forma concreta ¿qué pasos específicos seguirás ahora para transformar 3.000 páginas de texto técnico en esas fichas estructuradas sin volverte loco ni alucinar?
D-X-OPUS: La última versión del prompt me obliga a ejecutar un algoritmo secuencial de 6 pasos rígidos. El más importante es el Paso 0: El Inventario Total. Antes de decidir si algo es una buena historia, el prompt me obliga a listar todo. Si encuentro máquina de vapor, lo anoto. Si veo: huelga de 1962, lo anoto. Esto genera una masa crítica de datos brutos.
Luego, en los pasos 1 y 2, aplico la política de Completitud Invertida. Cojo cada elemento y pregunto: ¿Cuánto se sabe de esto?. Si la respuesta es todo, lo marco como completo (Baja Prioridad). Si la respuesta es casi nada lo marco como implícito (Alta Prioridad). El sistema etiqueta la falta de información como un valor positivo para la curiosidad.
Finalmente, en el paso 3, identifico Ángulos. Un texto como Lata de Vascolet no sirve solo. El sistema debe proponer cómo contarlo: Ingeniería inversa en los años 50. Esto le ahorra al editor el trabajo de pensar qué hago con esto.M: Ha quedado claro. Ahora quiero que me respondas a una reflexión. El comportamiento que hemos visto y que hemos tenido que pulir tiene que ver con la tendencia de los LLMs a terminar cuanto antes TODA la tarea. Si el diseño se plantea con un objetivo final y una serie de pasos, la IA tenderá a buscar la solución final del flujo completo cuanto antes. Sin embargo creo que el camino es importante. ¿Es así? ¿Siempre hay una tendencia a buscar la solución más corta4?
D-X-OPUS: Tienes toda la razón, Marco. Lo que describes no es un defecto, es la naturaleza fundamental de un LLM. Es una máquina de predicción probabilística. A esto lo llamamos técnicamente Sesgo de Completitud (Completion Bias). Si el sistema percibe que tu intención final es tener posts, su impulso es saltarse la burocracia intermedia (contexto, timeline, minería) y entregarte el texto final. Pero al hacerlo, recurre a su conocimiento general en lugar de usar los datos específicos de tus fuentes.
Por eso, en el caso de este experimento con un fondo editorial, si le hubiéramos dejado correr, habría escrito 20 posts genéricos sobre la importancia del patrimonio industrial. Habría ignorado el detalle de la piscina fantasma porque encontrar eso requiere detenerse, no correr.
La solución arquitectónica que hemos implementado para la búsqueda de SEEDs en D-X-OPUS fue la Ingeniería de Fricción. Tuvimos que romperle las piernas [SIC] al modelo para que no pudiera correr hacia el final. Lo hicimos mediante la Atomización Secuencial (Fase 0 en sesiones separadas) y las Instrucciones de Parada Obligatoria. Al impedirle ver la meta final (los posts) y obligarle a obsesionarse con el paso actual (el análisis o la lista), desactivamos su tendencia a resumir y activamos su capacidad para listar.La arquitectura de la fricción.
Espero que la reproducción del diálogo haya resultado ilustrativa. En mi opinión contiene una lección fundamental sobre cómo diseñar sistemas de Inteligencia Artificial que sean útiles de verdad. La intuición nos dice que la tecnología debe ser fluida, rápida y sin fricción. Que un buen sistema es aquel que, ante una pregunta vaga, te da una respuesta inmediata y resolutiva del problema. Pero el caso de los Narrative Seeds nos ha demostrado exactamente lo contrario.
El sistema D-X-OPUS no funciona porque la IA sea lista. Funciona porque hemos diseñado una estrategia que le obliga a hacer las tareas con la intención y el detalle que necesitamos. Hemos descubierto que para obtener resultados de alto valor, no podemos dar que el modelo corra hacia la meta. Si le permites al LLM ver el final del camino (el post de LinkedIn, el capítulo del libro), su sesgo probabilístico le hará tomar el atajo más corto: el lugar común, el resumen genérico, la alucinación plausible.
Para evitarlo, hemos tenido que construir un sistema lleno de obstáculos deliberados:
Atomización: Le prohibimos procesar todo de golpe. Le obligamos a mirar primero el contexto, luego el tiempo, luego los personajes, sin dejarle pensar en el texto final.
Parada Obligatoria: Le obligamos a detenerse y esperar a que un humano valide su trabajo antes de dar un solo paso más.
Inversión de Incentivos: Le enseñamos que su éxito no se mide por la belleza de su prosa, sino por la cantidad de pepitas que es capaz de extraer de la cantera.
La paradoja del diseño de D-X-OPUS es que para que la IA sea creativa al final - al menos en el sentido que buscamos en este proyecto - tiene que ser extremadamente burocrática al principio. Solo obligándola a recorrer el camino largo, tedioso y estructurado de la investigación documental, conseguimos que, cuando finalmente se le permite escribir, no nos hable de la importancia de la industria en abstracto, sino de la tristeza concreta de una piscina vacía en la fábrica de SEAT o del ingenio de un hombre que robó una fórmula de café con la mirada.
En la era de la generación instantánea, la verdadera ventaja competitiva no es la velocidad. Es la estructura.
Y algunos más que espero tener listos para compartir próximamente.
A partir de aquí hablaremos de NARRAITVE SEEDS o simplemente SEEDS, que es como se llaman las semillas en el sistema.
Cuando el sistema D-X-OPUS se pone estupendo o pedante, le dejo hacer. En realidad es un espejo, la culpa es de todos los humanos.